
As GPU clusters and AI workloads grow in scale and complexity, optical interconnects have become the backbone of high-performance data center networks. The surge in AI models, particularly large language models (LLMs), has placed immense bandwidth, latency, and scalability demands on interconnects. From understanding module technologies to deploying AI-specific network fabrics and managing power constraints, the decisions data center engineers make today dictate performance, efficiency, and long-term scalability. This article explores the nuanced landscape of optical interconnects: the physical layer technologies enabling these systems, network topology design for large-scale AI workloads, power and thermal trade-offs, industry standards, and evolving deployment roadmaps. Each chapter connects these critical elements to help decision-makers design state-of-the-art AI infrastructures with precision and foresight.
Choosing the Physical Layer: Optical Modules, Media, and Reach for Scalable GPU Clusters and AI Fabrics

The physical layer determines whether an AI fabric is merely fast on paper or efficient at scale. Inside a server, GPU-to-GPU and CPU-to-GPU links usually remain electrical because they favor extreme bandwidth, very low latency, and tight power control over short distances. The optical decision begins once traffic leaves the node and enters the rack, row, or broader fabric. At that point, the right choice is less about a single module type and more about matching reach, lane speed, power, and service model to collective-heavy traffic.
For very short connections, copper still has a clear role. Direct-attach cables offer the lowest power and latency, but their reach is limited. Active electrical cables extend that range slightly, though with more power and added retiming. Active optical cables become attractive when operators want cleaner cable handling and longer intra-rack or row-scale runs. Even so, structured single-mode fiber is becoming the default foundation for new AI builds because it supports a cleaner migration path from 400G to 800G and then to 1.6T.
That makes intensity-modulated direct-detect optics the practical workhorse. At 400G, short-reach parallel single-mode modules fit leaf and top-of-rack links well, while duplex 2 km options simplify cabling where patch panels and row aggregation matter. At 800G, the same pattern holds: parallel optics are strong for rack-to-rack spans, while duplex 2 km designs are better when operators want lower fiber counts and simpler operations. A useful overview of these tradeoffs appears in this guide to 400G vs 800G transceivers. For large AI clusters, 800G is increasingly the baseline because endpoint bandwidth is rising quickly and high-radix switching reduces the number of costly hops.
The harder choice is no longer only reach. It is also latency per port, watts per bit, and serviceability under failure. Traditional DSP-based pluggables remain the safest option for interoperability and signal margin, especially over longer reaches. But they add power and measurable latency. Linear-drive optics reduce both, which matters in synchronized collectives where tail delay from the slowest flow sets iteration time. Their tradeoff is tighter channel control and a narrower operating envelope. Near-packaged and co-packaged optics push efficiency further by shrinking electrical paths, which will matter more as 224G electrical lanes drive 1.6T ports, but they complicate maintenance and sparing.
So the physical layer for GPU clusters is becoming clearer. Use copper where distance is minimal and every nanosecond counts. Use AOCs where operational simplicity wins. Use 400G mainly for transitional or smaller deployments. Use 800G single-mode optics as the current default for serious AI fabrics. And design the plant, connectors, and faceplate density now so that 1.6T adoption becomes an upgrade, not a rebuild.
Designing AI Network Fabrics: The Topologies and Protocols That Determine Optical Interconnect Needs
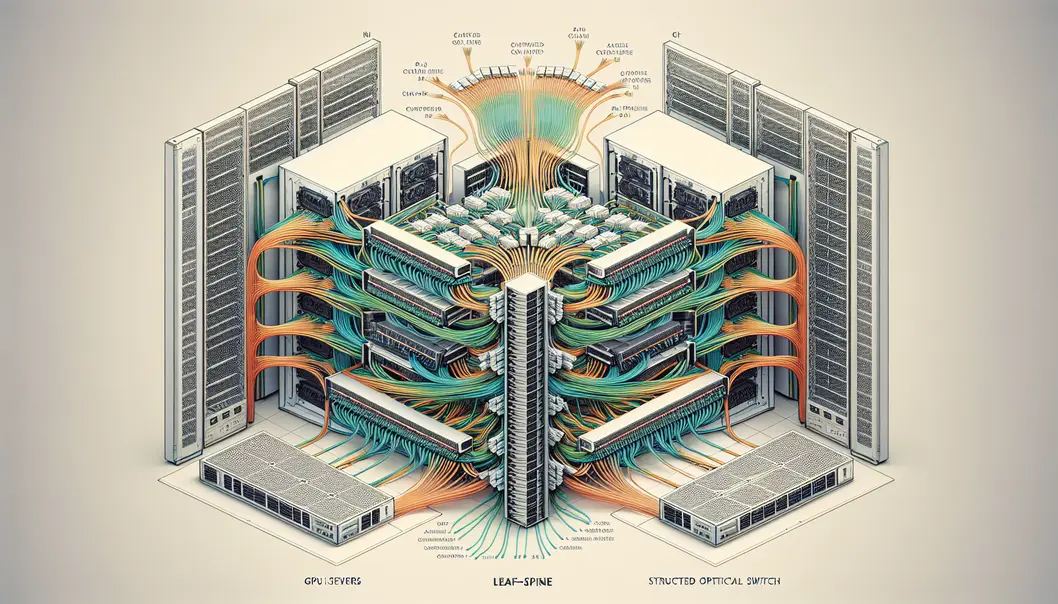
Once optical modules are chosen, the harder question is how the fabric will behave under AI traffic. GPU clusters do not generate smooth, random flows. They produce synchronized bursts from collective operations, where thousands of endpoints may enter the same exchange at once. That changes what the network must optimize. Raw bandwidth matters, but predictable completion time matters more. In training jobs, the slowest flow often sets the pace for the entire step.
This is why fabric design and optical interconnect planning are inseparable. A topology with too many hops adds delay at every switch and link. A fabric with oversubscription may look efficient on paper, yet perform poorly during AllReduce or AllGather phases. AI clusters therefore favor near non-blocking designs, often around 1:1 to 1.2:1, so collective traffic can move without severe head-of-line blocking or long tail latency. Folded-Clos remains the default because it scales cleanly and maps well to leaf-spine construction, but its optical demand rises quickly. Every additional stage increases transceiver count, fiber plant complexity, and power draw.
At larger scales, operators may consider dragonfly-like designs to reduce the number of global links, or mesh-style fabrics where deterministic paths are valued. The trade-off is operational complexity. These approaches can save ports, but they demand stricter traffic engineering and routing discipline. For most shared AI environments, simpler high-radix fabrics remain easier to tune and expand. That is especially true as 800G links become standard and migration toward 1.6T begins, a transition explored in more detail in this guide to 400G vs 800G transceivers.
Protocol choice is equally consequential. Lossless or near-lossless transport is not optional for collective-heavy workloads. Credit-based fabrics are attractive because they offer stable latency and bounded congestion behavior. Ethernet-based RDMA fabrics can also perform well, but only with disciplined congestion management, explicit marking, careful queue design, and enough buffering to absorb synchronized bursts. Otherwise, retransmissions and jitter erase the gains of fast optics. In-network reduction features further change the equation by shrinking the amount of traffic that must cross the fabric, which can delay expensive optical scale-outs.
Seen this way, the network fabric is not just the path optics must serve. It is the system-level constraint that determines whether a cluster needs short-reach row optics, longer duplex aggregation links, or a rapid move to higher radix and faster lanes. Optical interconnect requirements emerge from topology, transport behavior, and collective communication physics working together.
Power, Heat, and Packaging Choices That Define Optical Interconnects for AI GPU Fabrics

As AI clusters move from hundreds of GPUs to many thousands, optical interconnect selection becomes a power and thermal design problem as much as a bandwidth one. The fabric may be specified in terabits per second, but it is ultimately deployed in racks, switch faceplates, and cooling envelopes. That changes the answer to what optical interconnects are needed. The right choice is not simply the fastest module. It is the one that delivers required reach, latency, and density without overwhelming the power budget or making the network impossible to service.
This pressure is strongest at 800G now and will intensify at 1.6T. A high-radix switch filled with 800G optics can devote well over a kilowatt to optics alone. At 1.6T, early modules push that number much higher. In large AI fabrics, optics can account for a major share of total network power, which then becomes additional cooling load. That matters because collective-heavy training traffic is sensitive to throttling, hotspots, and failures caused by thermal stress. A fabric designed for theoretical throughput but deployed with marginal airflow will not behave like a low-jitter AI network in practice.
Packaging therefore matters as much as modulation. Traditional DSP-based pluggables remain attractive because they are modular, interoperable, and easier to replace in the field. They also tolerate longer reaches and more varied environments. But they consume more power and add measurable latency. Linear pluggable optics reduce both by removing the optical DSP, making them appealing for tightly controlled short-reach single-mode links inside AI rows. They are not a universal answer, though. Their benefits depend on clean channels, validated hosts, and disciplined operations. For many builders, that trade is worthwhile where every watt and nanosecond matter.
The next step is moving optics closer to the switch silicon. Near-packaged and co-packaged approaches reduce electrical loss, improve density, and create a better path to 224G lanes. Those gains are real, especially in dense AI core tiers where faceplate power and signal integrity become limiting factors. The cost is serviceability. Replacing a failed pluggable is operationally simple. Replacing optics tied closely to the switch package is not. That makes packaging strategy inseparable from sparing policy, maintenance workflows, and mean-time-to-repair targets.
For most current AI fabrics, the practical path is a layered one: use modular 400G and 800G optics where flexibility and field replacement dominate, adopt lower-power short-reach options where the environment is controlled, and reserve more aggressive packaging for the densest switching tiers. That migration is already shaping 400G and 800G optics for AI demand, and it will define how clusters scale without turning network power into the limiting resource.
Why Standards, Supply Chains, and Port Economics Shape Optical Interconnect Choices for GPU Clusters

The optical fabric in an AI cluster is chosen as much by economics and operational risk as by bandwidth. A design may look ideal on paper, yet fail in deployment if module supply is thin, standards are immature, or the cabling model raises port cost too quickly. That is why the practical answer to what optical interconnects are needed for GPU clusters and AI fabrics depends on a three-way balance: standards maturity, manufacturable volume, and the real cost of every additional GPU-facing link.
Standards matter because they determine how fast a cluster can scale without locking the operator into fragile exceptions. The current build-out center of gravity sits around 400G and 800G PAM4 optics, backed by well-understood forward error correction, common form factors, and established single-mode reaches. That maturity reduces qualification effort and improves multivendor sourcing. It also explains why 400G DR4 and FR4 remain relevant even as 800G expands. They are not just slower options. They are stable building blocks for transitional tiers, breakouts, and staged rollouts. For teams comparing lane counts, reaches, and migration paths, this overview of 400G versus 800G transceivers reflects the decisions many AI network planners now face.
Supply chain realities then narrow the menu further. High-speed optics depend on lasers, DSPs, advanced packaging, and test capacity that do not scale overnight. When demand spikes, the highest-volume standards usually win because they are easier to source and replace. That gives standardized DR and FR classes an advantage over niche variants. It also favors pluggable designs in many deployments, since field replacement is simpler and spare strategies are clearer. Early 1.6T optics are strategically important, but they will enter clusters first where density pressure justifies premium pricing and longer qualification cycles.
Port economics ties these choices back to AI performance. Collective-heavy fabrics need many high-speed ports, often with very low oversubscription. That makes optics cost a fabric-level issue, not a line-item detail. A slightly more expensive module may still lower total system cost if it cuts fiber count, reduces switch stages, or delays a chassis upgrade. Conversely, the cheapest module can become expensive if it increases cabling complexity, consumes scarce faceplate density, or fragments the spare pool. This is why operators often standardize on a small optical set: short-reach options for server attachment, DR-class optics for row-scale links, FR-class optics for aggregation, and a clear migration path toward 1.6T once 200G-per-lane ecosystems and supply volumes stabilize.
From 400G to 1.6T: Practical Deployment Roadmaps for Optical Interconnects in GPU Clusters and AI Fabrics

After standards, cost, and supply realities are understood, deployment planning becomes a question of where each optical class belongs as GPU clusters grow. The answer is rarely a single media choice. It is a staged roadmap tied to reach, radix, latency, and how quickly the fabric must scale from one row to many rows or even multiple buildings.
For smaller GPU environments, the first step is usually simple and disciplined. Inside a rack, copper or short active cables remain the best fit when reach allows, because they preserve power and latency budgets. The optical decision begins at the rack boundary. When structured single-mode cabling is already in place, 400G DR4 offers a clean starting point for server-to-switch and switch-to-spine links within a row. Where operators want longer flexibility with simpler duplex cabling, FR4 becomes attractive, though with a higher power and cost profile. This is also the stage where many teams decide whether they are building merely for current training jobs or for the next doubling of endpoint bandwidth. That choice often determines whether 400G is a bridge or a platform. A useful reference for this transition is 400G vs 800G transceivers, especially when balancing migration timing against cabling reuse.
As clusters move into several thousand GPUs, the roadmap shifts decisively toward 800G optics. Aggregate node bandwidth is rising faster than operators can tolerate extra network tiers, so higher-radix switching and denser optical uplinks matter more than incremental port savings. In practice, 800G DR8 becomes the common short-reach single-mode building block for rack-to-rack and row-scale connectivity, while 800G 2xFR4 fits aggregation paths that stretch farther across halls. This mix supports near-non-blocking folded Clos designs without exploding fiber plant complexity. It also creates cleaner breakout paths, such as splitting one 800G uplink into two 400G links during phased expansion.
At larger scales, the roadmap is no longer just about speed. It becomes about power density and hop control. A fabric with synchronized collectives cannot hide latency inflation from extra stages, heavy DSP processing, or thermal throttling. That is why short-reach environments are increasingly evaluating linear pluggable optics to trim both watts and nanoseconds, while the densest core tiers are preparing for near-packaged or co-packaged approaches once 224G electrical lanes push conventional front-panel designs too far.
That makes 1.6T less a luxury than the next logical step for very large AI fabrics. It reduces faceplate pressure, cuts the number of optical endpoints needed for a given fabric bandwidth, and helps preserve low-stage topologies as clusters approach campus scale. The practical roadmap, then, is not a sudden leap. It is a controlled progression: 400G for transitional builds, 800G as the present mainstream, and 1.6T as the scale-preserving layer for the next generation of GPU clusters.
Final thoughts
Optical interconnects are the foundation of modern AI and GPU cluster networks, supporting their need for bandwidth, scalability, and reliability. As data center operators plan for the future, selecting and deploying 400G and 800G optics today, while preparing for 1.6T advancements, ensures operational excellence. Careful consideration of power, thermal trade-offs, and established versus emerging standards will lead to systems that efficiently handle the exponential growth in AI workloads. Whether managing a small GPU cluster or a hyperscale AI deployment, understanding the landscape of optical technologies and their integration will empower teams to build robust, future-ready infrastructures.
Talk to ABPTEL about high-speed optics, MTP/MPO cabling, and data center interconnect solutions to upgrade your AI infrastructure.
Learn more: https://abptel.com/contact/
About us
ABPTEL provides high-speed optical transceivers, MTP/MPO cabling systems, DAC and AOC cables, PoE switches, FTTA solutions, and fiber tools. Ideal for data center, AI, telecom, and network projects, our solutions optimize performance, scalability, and efficiency, ensuring businesses stay ahead in demanding environments.




